
ถ้า Sitemap คือ "แผนที่" ที่เรายื่นให้ Google...
robots.txt ก็คือ "ป้อมยาม" หน้าหมู่บ้านครับ
มันคือไฟล์ข้อความธรรมดา ๆ (Text File) ที่วางอยู่หน้าบ้านของเรา เพื่อคอยตะโกนบอกบอตทุกตัวที่เดินผ่านมาว่า:
"เฮ้ย! ห้องนี้เข้าได้นะ ส่วนห้องเก็บของหลังบ้านห้ามเข้า!"
ในบทนี้เราจะมาเรียนรู้วิธีสั่งการป้อมยามนี้ให้แม่นยำ เพื่อรักษา Crawl Budget (โควตาการเก็บข้อมูล) ไว้ให้เฉพาะหน้าสำคัญเท่านั้นครับ
Note: ถ้าพื้นฐาน SEO ยังไม่แน่น แนะนำศึกษาเพิ่มเติมใน Ep 1: SEO คืออะไร? ก่อนนะครับ จะได้เข้าใจว่าทำไมเราต้องแคร์เรื่อง Bot ครับ
1. Robots.txt คืออะไร?
Robots.txt คือไฟล์ข้อความที่วางอยู่ที่ Root Directory ของเว็บไซต์ (example.com/robots.txt) ใช้สำหรับควบคุมบอตของ Search Engines (เช่น Googlebot, Bingbot) ว่าหน้าไหน "อนุญาต" หรือ "ไม่อนุญาต" ให้เข้ามาเก็บข้อมูล (Crawl)
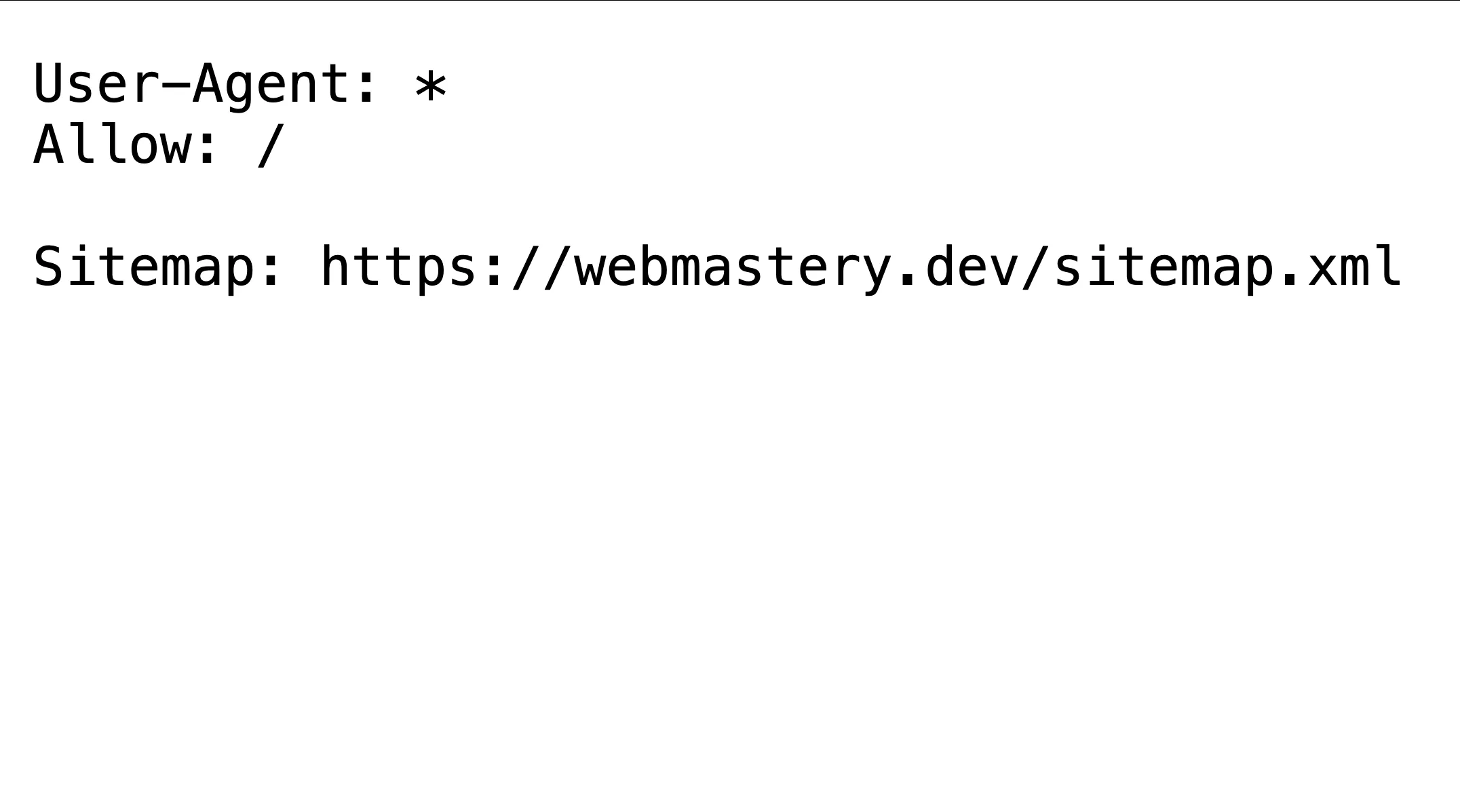
ตัวอย่าง robots.txt (ของ Web Mastery)
ทำไมต้องมี?
- Crawl Budget Optimization: ช่วยประหยัดงบการ Crawl ทำให้มั่นใจว่าบอตจะไปเก็บเฉพาะหน้าคุณภาพที่มีโอกาสได้ Traffic จริงๆ (ไม่ใช่ไปเสียเวลากับหน้า Admin)
- Server Resources: ลดภาระการทำงานของเซิร์ฟเวอร์ ประหยัด Bandwidth จากการที่บอตมารุมทึ้งหน้าเว็บที่ไม่จำเป็น
- Privacy Control: ป้องกันไม่ให้บอตเข้าถึงหน้าส่วนตัว เช่น Dashboard ผู้ใช้ หรือหน้า Staging (UAT)
2. รู้จักชื่อบอต (User-agent)
ก่อนจะสั่งงาน เราต้องรู้ก่อนว่าเรากำลังคุยกับใคร นี่คือรายชื่อบอตที่เรามักเจอใน Robots.txt ของเว็บใหญ่ ๆ ครับ
| ชื่อบอต (User-agent) | เจ้าของ |
|---|---|
| Googlebot | Google (ตัวหลัก) |
| Googlebot-Mobile | Google (สำหรับมือถือ) |
| Bingbot | Bing |
| Baiduspider | Baidu (จีน) |
| Slurp Bot | Yahoo |
| DuckDuckBot | DuckDuckGo |
* (Wildcard) |
บอตทุกตัวในโลก |
ตัวอย่างจาก Shopee:
เว็บ E-commerce ใหญ่ ๆ มักจะระบุชื่อบอตชัดเจนแบบนี้ครับฝฦ
User-agent: Googlebot
Disallow: /buyer/
...
User-agent: Bingbot
Disallow: /buyer/
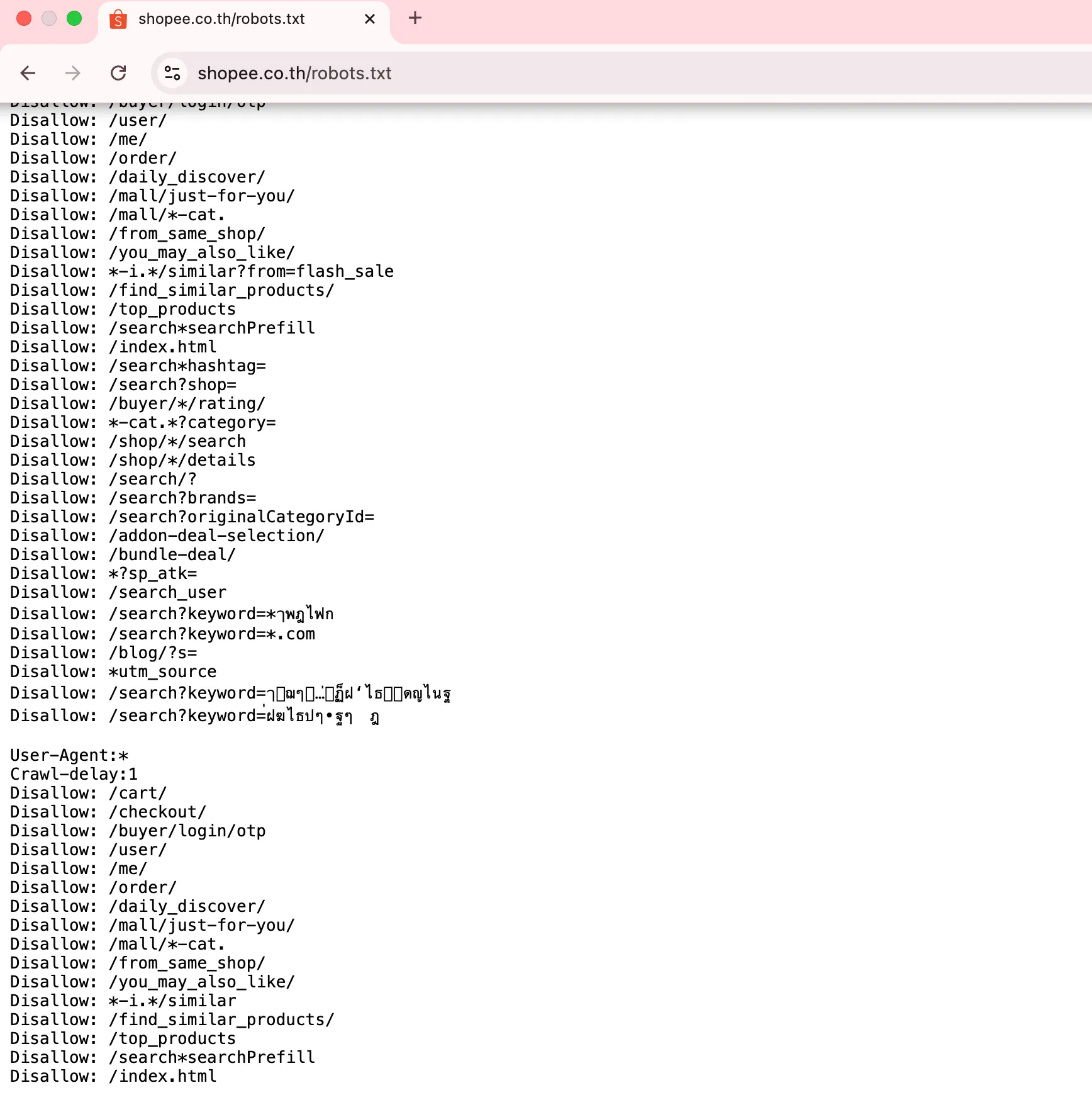
ตัวอย่างไฟล์ robots.txt ของเว็บไซต์ Shopee ที่ใช้กำหนดกฎการเข้าถึงของ Search Engine Bot เพื่อควบคุมการ crawl หน้าเว็บไซต์ และจัดการ crawl budget สำหรับเว็บไซต์ขนาดใหญ่
3. โครงสร้างคำสั่ง
โครงสร้างไฟล์นี้เข้าใจง่ายมากครับ มีแค่ User-agent (บอกว่าคุยกับใคร) และ Disallow/Allow (บอกว่าห้ามหรือให้เข้า)
A. User-agent & Disallow
- User-agent: ชื่อบอต (ใช้
*ถ้าจะเหมาหมด) - Disallow: เส้นทาง (Route) ที่ห้ามเข้า
ตัวอย่างการเขียนแบบมืออาชีพ:
อันนี้เป็น Code Template ที่คุณสามารถนำไปประยุกต์ใช้ได้เลยครับ (เครดิต: Content Mastery)
User-agent: *
# 1. ห้ามเข้าถึงหน้าผู้ใช้และข้อมูลส่วนตัว
Disallow: /user/
Disallow: /account/
Disallow: /profile/
Disallow: /dashboard/
# 2. ห้ามเข้าถึงหน้าแอดมิน (สำคัญมาก!)
Disallow: /admin/
Disallow: /wp-admin/
# 3. ห้ามเข้าถึงไฟล์ระบบ
Disallow: /cgi-bin/
Disallow: /tmp/
Disallow: /.htaccess
# 4. ห้ามเข้าถึงหน้าผลการค้นหา (Search Result Pages)
# เหตุผล: หน้าเสิร์ช (เช่น /search?q=...) สร้าง URL ได้ไม่จำกัด (Unlimited URLs)
# เราไม่ควรให้ Google เสียเวลามาเก็บหน้านี้ เพราะเนื้อหามันซ้ำและไม่มีคุณภาพในสายตา SEO
Disallow: /search/
Disallow: /search?q=
# 5. แจ้งพิกัดแผนที่ (Sitemap)
Sitemap: https://www.example.com/sitemap.xml
B. Allow (อนุญาต)
ใช้ในกรณีที่เราสั่ง Disallow โฟลเดอร์ใหญ่ไปแล้ว เเต่อยาก "ยกเว้น" ไฟล์บางตัวข้างในให้บอตเข้าได้
- ตัวอย่าง: ห้ามเข้าโฟลเดอร์
/uploads/ทั้งหมด แต่ขอเปิดให้เข้าไฟล์.jpgได้
User-agent: *
Disallow: /uploads/
Allow: /uploads/*.jpg
4. ข้อควรระวัง
การแก้ไฟล์ Robots.txt เหมือนการผ่าตัดครับ ผิดนิดเดียวชีวิตเปลี่ยน
-
ห้าม Disallow Root:
* ❌Disallow: /คำสั่งนี้คือ "ห้ามบอตเข้าเว็บไซต์ฉันแม้แต่หน้าเดียว" (มักลืมเอาออกตอนเอาเว็บขึ้น Production เว็บหายเกลี้ยง!) -
ระวัง Disallow CSS/JS:
* ถ้าเราเผลอไปบล็อกไฟล์.cssหรือ.jsGooglebot จะ Render หน้าเว็บเราไม่ออก (เห็นเป็นหน้าพังๆ) ส่งผลเสียต่ออันดับทันที
5. Robots.txt vs Meta Noindex (ต่างกันยังไง?)
หลายคนสับสน 2 ตัวนี้ครับ มาดูตารางเปรียบเทียบชัดๆ
| คุณสมบัติ | Robots.txt (Disallow) | Meta Tag (Noindex) |
|---|---|---|
| คำสั่ง | "ห้ามเดินเข้าไปนะ" | "เดินเข้ามาได้ แต่ห้ามจดบันทึก (ห้าม Index)" |
| ผลลัพธ์ | Google ไม่เห็นเนื้อหาข้างใน (แต่ URL อาจยังโชว์บน Google ได้ ถ้ามีคนลิงก์มาหา) | Google เข้ามาเห็นเนื้อหา แต่ จะไม่โชว์หน้านี้บนผลการค้นหา 100% |
| ใช้เมื่อไหร่ | ประหยัด Crawl Budget (หน้า Admin, Script, Search Page) | ต้องการซ่อนหน้าที่มีเนื้อหา (เช่น Thank You Page, Landing Page เฉพาะกิจ) |
สรุป Checklist สำหรับ Ep 4
- [ ] ตรวจสอบว่าไฟล์ชื่อ
robots.txt(ตัวพิมพ์เล็กทั้งหมด) และอยู่ที่ Root Domain - [ ] ตรวจสอบบรรทัด
Disallowว่าไม่ได้เผลอบล็อกหน้าสำคัญ - [ ] เพิ่มบรรทัด
Sitemap: ...ไว้ล่างสุด - [ ] ถ้าเว็บขนาดเล็กมาก (มีไม่กี่หน้า) ไม่ต้องมีไฟล์นี้ก็ได้ ครับ (Google ฉลาดพอที่จะ Crawl ทั้งหมด) แต่ถ้าเว็บเริ่มมีหน้าเยอะหลักพันหลักหมื่น ต้องมีครับ!
เมื่อเราคัดกรอง bots หรือ crawlers ที่จะมาเก็บเกี่ยวข้อมูลเว็บเราได้แล้ว (robots.txt) ต่อไปเราจะไปสร้าง "แผนที่นำทาง" เพื่อยื่นให้ Googlebot เดินสำรวจหน้าสำคัญได้ครบทุกซอกทุกมุม ใน Ep 5: XML Sitemaps Strategy ครับ
อ้างอิงเพิ่มเติม: